Concepts #
Deep Generative Models #
VAE #
Flow-based #
- Invertible Neural Network
- Normalizing Flow (Flow Neural Network) [Note]
- Denoising Normalizing Flow
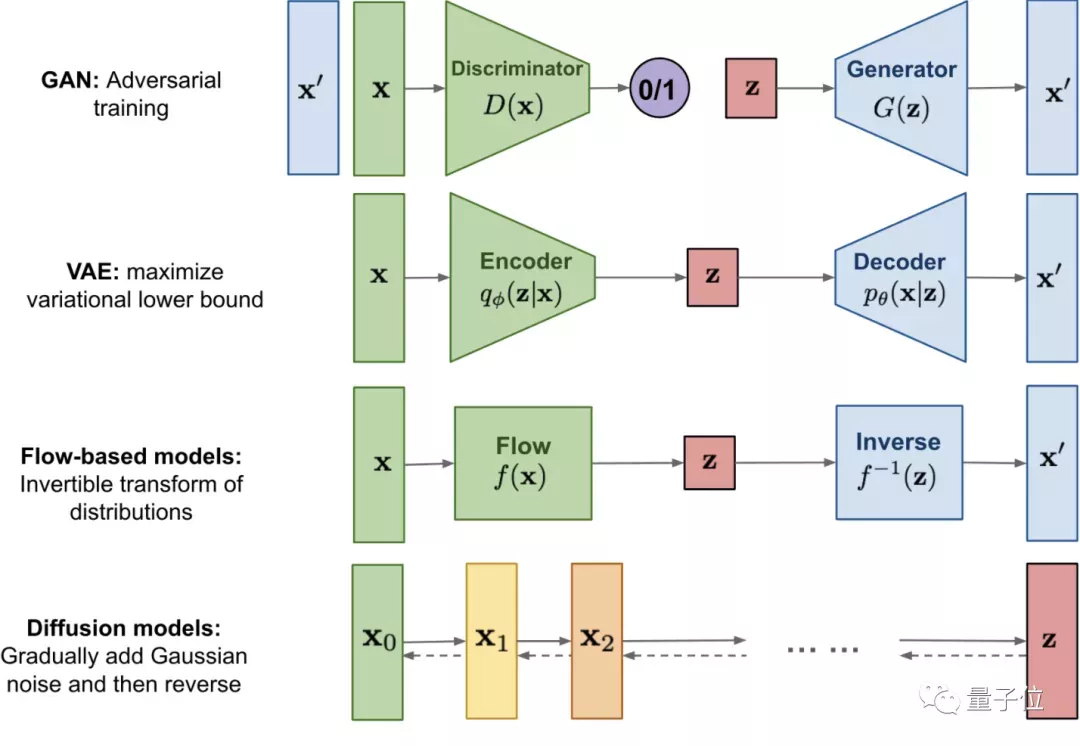
Illustration
EM #
ADMM #
Others #
- Denoising Autoencoder
朴素贝叶斯 #
朴素贝叶斯
用于求解分类问题,给定数据,每个数据点包含多列特征和一个类别。 任务是估计给定特征,各个类别出现的概率,即求: $$ p\left(C \mid F_{1}, \ldots, F_{n}\right) $$
我们可以用频率估计概率的方法直接从数据中估计这个概率,但是当特征F的种类很多,取值也很多的情况下,我们需要很大量的数据才能做出准确估计。这在现实生活中往往是做不到的。
因此,朴素贝叶斯首先用贝叶斯公式改写求解目标: $$ p\left(C \mid F_{1}, \ldots, F_{n}\right)=\frac{p(C) p\left(F_{1}, \ldots, F_{n} \mid C\right)}{p\left(F_{1}, \ldots, F_{n}\right)} $$
分母是每个特征出现的联合概率,与类别无关,可以看作某个未知的定值。对于分子,$p(C)$是比较容易通过频率估计的,而$p\left(F_{1}, \ldots, F_{n} \mid C\right)$则不好估计,因为当特征F很多的时候,数据一般比较稀疏,给定$C$,$F_{1}, \ldots, F_{n}$出现的概率可能为0,因为数据集中不存在这种情况(但不代表真的出现概率为0)。
因此,朴素贝叶斯做了个朴素的假设,即各个特征相互独立。基于此,则有:
$$
\begin{equation}
\begin{aligned}
p\left(F_{1}, \ldots, F_{n} \mid C\right) & \propto p\left(F_{1} \mid C\right) p\left(F_{2} \mid C\right) p\left(F_{3} \mid C\right) \ldots \\
& \propto \prod_{i=1}^{n} p\left(F_{i} \mid C\right)
\end{aligned}
\end{equation}
$$
显然,基于频率统计概率$p\left(F_{i} \mid C\right)$会更加容易得多。